Disponible avec une licence Business Analyst.
Le processus d’analyse d’adéquation identifie les sites qui correspondent aux critères que vous définissez. Les critères d’adéquation peuvent être les suivants :
- Variables du navigateur de données, telles que la densité de la population, les revenus du foyer ou le trafic quotidien moyen annuel
- Champs d’une couche en entrée, comme des attributs de site
- Localisation des points d’une couche
Les critères sont prétraités, combinés et mis à l’échelle pendant l’analyse. Chaque variable peut également être pondérée pour définir son influence dans l’analyse. À l’issue de l’analyse d’adéquation, chaque site obtient un score et un score pondéré. Les résultats s’affichent dans la fenêtre Résultats, dans la couche de l’analyse d’adéquation qui est ombrée sur la carte, ainsi que dans la table attributaire du site candidat.
Exemple
Une chaîne de restaurants souhaite se développer sur de nouveaux marchés. L’équipe marketing de la société a analysé les facteurs qui ont contribué au succès de la localisation des restaurants, comme une forte population en journée, la proximité de sociétés complémentaires et des zones à forte densité de population. La société va utiliser ces critères pour effectuer une analyse d’adéquation des groupes d’îlots dans le comté de Dane, dans le Wisconsin. Les scores d’adéquation des sites sont renvoyés dans trois endroits : un codage couleur des groupes d’îlots sur la carte, dans la table attributaire et dans la fenêtre Résultats.
Résultats
Vous pouvez afficher les résultats de l’analyse sous forme d’une couche de carte dans laquelle le site a un code couleur qui représente son score d’adéquation, et dans la fenêtre Résultats qui comprend un Récapitulatif  , un Histogramme
, un Histogramme  , un Nuage de points
, un Nuage de points  et une Table
et une Table  . Pour en savoir plus sur la fenêtre Résultats de l’analyse d’adéquation, consultez la rubrique Explorer les résultats.
. Pour en savoir plus sur la fenêtre Résultats de l’analyse d’adéquation, consultez la rubrique Explorer les résultats.
Calculs
Les paramètres qui indiquent les calculs du score de chaque variable se trouvent dans la fenêtre Suitability Analysis (Analyse d’adéquation). La fenêtre Analyse d’adéquation comprend deux sections permettant de modifier les calculs : l’onglet Critères, qui permet d’affiner les critères d’analyse, et l’onglet Paramètres, qui permet de modifier la méthode de notation et la pondération des critères.
Critère
L’onglet Critères comporte des options permettant de modifier les critères, par exemple de modifier le type de calcul, l’influence et la plage de valeurs minimale et maximale.
1 | Nom du critère | Nom attribué au critère. |
2 | Paramètre Influence | Affiche l’influence de vos critères à l’aide des options d’influence positive, inverse, idéale ou site cible. Par défaut, l’influence de chaque critère d’adéquation est positive si aucun site cible n’est défini. Si un site cible est défini, l’influence par défaut est la cible. |
3 | Histogramme | Affiche la distribution des valeurs des critères. La valeur idéale ou le site cible, si l’un ou l’autre est défini, s’affiche dans la distribution. |
4 | Filtre | Ajustez les poignées du curseur pour définir les valeurs minimale et maximale dans l’analyse ou saisissez manuellement les valeurs. |
5 | Afficher les résultats | Cliquez sur ce bouton pour ouvrir la fenêtre Résultats. |
Le calcul commence par convertir chaque valeur v en fonction de l’influence pour générer une nouvelle valeur v. L’influence peut être définie comme positive, inverse, idéale ou site cible. Les calculs de l’influence sont les suivants :
| Influence | Description | Calcul |
|---|---|---|
Positive | Plus la valeur de la variable est élevée, plus elle a d’incidence sur le score final. |  |
Inverse | Plus la valeur de la variable est faible, plus elle a d’incidence sur le score. Elle est également désignée sous le nom d’influence négative. |  |
Idéale | Plus la valeur de la variable est proche de la valeur idéale spécifiée et plus elle a d’incidence sur le score. |  |
Site cible | Plus la valeur de la variable est proche de la valeur du site cible du critère, plus elle a d’incidence sur le score. | 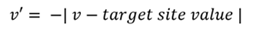 |
Notation
Les scores d’adéquation sont utilisés pour représenter les informations de plusieurs critères sous forme d’un score unique. Les scores d’adéquation sont calculés à l’aide de méthodes dans un processus en quatre parties : prétraitement, pondération, combinaison et mise à l’échelle du score final. Pour modifier les paramètres du score d’adéquation, cliquez sur l’onglet Paramètres dans la fenêtre Analyse d’adéquation, puis sur Notation.
Sélectionner une méthode de notation prédéfinie ou personnalisée
Dans Business Analyst, vous avez le choix entre deux méthodes prédéfinies de prétraitement et de combinaison des critères. Si vous optez pour une des méthodes prédéfinies, les paramètres de prétraitement et de combinaison sont automatiquement sélectionnés. Vous pouvez également choisir une méthode personnalisée. Le menu déroulant Preset methods (Méthodes prédéfinies) comporte trois options :
- Combiner les valeurs (par défaut) : cette option additionne les valeurs mises à l’échelle des critères de sorte que chaque critère contribue de manière égale au score final.
- Elle utilise la méthode MinMax pour le prétraitement.
- Elle utilise la méthode Somme pour la combinaison.
Cette méthode prédéfinie est utile pour évaluer l’effet combiné de tous les critères, mais ses résultats sont influencés par les points aberrants. Les valeurs extrêmes peuvent avoir un impact disproportionné sur le score final.
- Différences composites : cette option utilise la moyenne géométrique des valeurs mises à l’échelle.
- Elle utilise la méthode MinMax pour le prétraitement.
- Elle utilise la méthode Moyenne géométrique pour la combinaison.
Cette méthode prédéfinie est utile lorsque les unités ou les échelles des critères sont différentes et si les différences relatives entre les valeurs doivent être mises en évidence. Ses résultats sont moins influencés par les points aberrants, ce qui est utile lorsque les critères contiennent des pourcentages ou des taux. Les scores ne sont élevés que s’il existe des valeurs élevées pour plusieurs critères. Par conséquent, une valeur extrême dans un seul critère ne peut pas avoir un impact disproportionné sur le score.
- Personnalisé : cette option permet de sélectionner les méthodes de prétraitement et de combinaison, qui sont décrites plus en détail ci-dessous.
Sélectionner une méthode de prétraitement
Le prétraitement standardise les variables sur une échelle commune. Si vous avez sélectionné l’option Personnalisé dans le menu déroulant Méthodes prédéfinies, le paramètre Méthode de prétraitement vous permet de sélectionner une méthode de mise à l’échelle commune. La méthode sélectionnée s’applique à toutes les variables, et les champs qui en résultent sont fournis dans la sortie.
Les méthodes de prétraitement et leurs calculs sont les suivants :
| Méthode de prétraitement | Description | Calcul |
|---|---|---|
MinMax | Cette méthode de prétraitement met à l’échelle les variables entre 0 et 1 en utilisant les valeurs minimale et maximale de chaque variable. Il s’agit de la méthode la plus simple dans la mesure où elle préserve la distribution des variables en entrée et utilise une échelle de 0 à 1 facile à interpréter. Toutefois, les points aberrants dans les données ont un impact sur le score. |
|
Centile | Cette méthode de prétraitement convertit les variables en centiles compris entre 0 et 1 via la mise à l’échelle du classement des valeurs de données. Utilisez la mise à l’échelle en centiles pour classer les sites en fonction de leur positionnement par rapport aux autres plutôt que par la magnitude réelle des valeurs, surtout si les données sont asymétriques ou comportent de nombreux points aberrants. Avec cette méthode, les points aberrants ou les distributions asymétriques n’ont pas d’impact sur le score. |
|
ZScore | Cette méthode de prétraitement standardise chaque critère en soustrayant la valeur moyenne de la valeur d’origine et en divisant le résultat par l’écart type (ou score z). Le score z est le nombre d’écarts types au-dessus ou au-dessous de la valeur moyenne. Cette méthode est utile pour créer une échelle commune en standardisant les données dont les unités sont différentes. Les valeurs supérieures à la moyenne reçoivent des scores z positifs, tandis que les valeurs inférieures à la moyenne reçoivent des scores z négatifs. |
|
Raw | Cette option utilise les valeurs d’origine de la variable. Aucun prétraitement n’est appliqué de sorte que l’échelle des critères en entrée est conservée dans les données. Cette méthode est utile lorsque les critères se trouvent sur une échelle comparable, comme des valeurs de pourcentage, ou s’ils ont déjà été prétraités avec d’autres outils. |
|


")

Sélectionner une méthode de combinaison
La combinaison associe les variables en une valeur unique. Si vous avez sélectionné l’option Personnalisé dans le menu déroulant Méthodes prédéfinies, le paramètre Méthode de combinaison vous permet de sélectionner une méthode de combinaison.
Les méthodes de combinaison et leurs calculs, où c est le nombre de critères, sont les suivants :
| Méthode de combinaison | Description | Calcul |
|---|---|---|
Somme | Cette méthode de combinaison additionne les scores pondérés. Cette méthode est non multiplicative, ce qui signifie que les pondérations sont appliquées en multipliant chaque critère par sa pondération respective. |
|
Moyenne | Cette méthode de combinaison utilise la moyenne des scores pondérés. Cette méthode est non multiplicative, ce qui signifie que les pondérations sont appliquées en multipliant chaque critère par sa pondération respective. |
|
Produit | Cette méthode de combinaison utilise le produit des scores pondérés. Cette méthode est non multiplicative, ce qui signifie que les pondérations sont appliquées en élevant chaque critère à la puissance de sa pondération respective. |
|
Moyenne géométrique | Cette méthode de combinaison utilise la moyenne géométrique des scores pondérés. Cette méthode est non multiplicative, ce qui signifie que les pondérations sont appliquées en élevant chaque critère à la puissance de sa pondération respective. |
|
")
")
")
")
Remarque :
Si vos critères contiennent des valeurs négatives et si vous avez sélectionné la méthode de prétraitement Brute, le fait de sélectionner Produit ou Moyenne géométrique dans le menu Méthode de combinaison produit des scores de critères nuls. Ces valeurs nulles ne sont pas prises en compte dans le score final.
Sélectionner une méthode de mise à l’échelle du score final
La mise à l’échelle du score final convertit le score combiné en valeurs de score final significatives. Vous pouvez utiliser le paramètre Mise à l’échelle du score final pour sélectionner une méthode de score final.
Les méthodes de mise à l’échelle du score final et leurs calculs sont les suivants :
| Méthode de score final | Description | Calcul |
|---|---|---|
0-1 | Cette méthode de mise à l’échelle du score final calcule un score final avec la valeur inférieure égale à 0 et la valeur supérieure égale à 1. Dans la plage comprise entre 0 et 1, toutes les autres valeurs sont mises à l’échelle proportionnellement. |
|
0-100 | Cette méthode de mise à l’échelle du score final calcule un score final avec la valeur inférieure égale à 0 et la valeur supérieure égale à 100. Dans la plage comprise entre 0 et 100, toutes les autres valeurs sont mises à l’échelle proportionnellement. |
|
Aucun | Cette option n’applique pas de mise à l’échelle et laisse les données intactes. Cette option est utile si la distribution des valeurs combinées doit être conservée. |
|
")
")
")
Pondération des critères
Les pondérations de critères représentent l’importance relative de chaque critère eu égard à sa contribution au score final. Pour modifier les paramètres de pondération, cliquez sur l’onglet Paramètres dans la fenêtre Analyse d’adéquation, puis sur Pondération. La section Pondération répertorie les critères et leur pondération dans l’analyse. Les pondérations des critères d’adéquation sont identiques par défaut. Cependant, si certains facteurs sont plus importants que d’autres, des pondérations différentes peuvent être appliquées.
Deux techniques de pondération sont disponibles :
- Pourcentage du total
- Relatif
Pourcentage du total
Vous pouvez définir les pondérations de critère sous forme de pourcentage du total, toutes les pondérations de tous les critères totalisant 100 %. Si vous augmentez ou diminuez la pondération de l’un des critères, la pondération de chacun des critères restants est automatiquement réduite ou augmentée proportionnellement. Vous pouvez verrouiller les valeurs des critères en cliquant sur le bouton Verrouiller le critère  . Lorsque les pondérations sont réévaluées automatiquement suite à leur modification, les critères verrouillés sont exclus de ce calcul.
. Lorsque les pondérations sont réévaluées automatiquement suite à leur modification, les critères verrouillés sont exclus de ce calcul.
Par exemple, si parmi trois critères, l’un est deux fois plus important que les deux autres, utilisez les pondérations 50 %, 25 % et 25 %.
Relatif
Vous pouvez définir les pondérations des critères les unes par rapport aux autres. Toutes les pondérations ont la valeur 1 par défaut, ce qui signifie que chaque critère est pondéré de manière égale. Vous pouvez ajuster ces valeurs pour modifier l’importance d’un critère par rapport à tous les autres.
Par exemple, si vous changez la pondération d’un critère en lui attribuant la valeur 2 et conservez la pondération de 1 pour tous les autres, ce critère sera considéré comme deux fois plus important que les autres eu égard à sa contribution au score final.
Pondération et calcul du score
La méthode de combinaison que vous sélectionnez influe sur le mode d’application des pondérations. Selon votre sélection dans le menu Méthode de combinaison, la méthode est multiplicative ou non multiplicative. Avec les méthodes Somme et Moyenne, des pondérations sont appliquées en multipliant chaque critère par sa pondération respective. Avec les méthodes Produit et Moyenne géométrique, des pondérations sont appliquées en élevant chaque critère à la puissance de sa pondération respective.
Non multiplicatif (somme, moyenne) |  |
Multiplicative (multiplication, moyenne géométrique) |  |
Bonnes pratiques pour la définition de pondérations
Les valeurs de pondération peuvent avoir un impact considérable sur le score obtenu. Que vous choisissiez de conserver des pondérations équivalentes ou de les modifier pour favoriser certains critères, le choix de la pondération est subjectif et doit reposer sur une logique solide. Comme par la sélection des critères, prenez conseil auprès d’experts techniques pour définir les pondérations appropriées. Vous pouvez également définir les pondérations à l’aide d’autres méthodes, telles qu’un sondage d’opinion publique.
Symbologie
Un sous-ensemble de symbologieArcGIS Pro est fourni dans l’onglet Paramètres de la fenêtre Analyse d’adéquation. Vous pouvez personnaliser l’apparence et la construction de votre couche d’analyse d’adéquation à l’aide de paramètres qui seront conservés au fil des modifications apportées à votre analyse d’adéquation.
1 | Nombre de classes | Nombre de groupements de données symbolisés par des couleurs dans les données en sortie. |
2 | Combinaison de couleurs | Plage des couleurs utilisées pour représenter les données en sortie. La combinaison de couleurs sélectionnée est conservée lorsqu’une modification est apportée. |
3 | Méthode de classification | Méthode de classification utilisée pour classer des champs numériques pour la symbologie graduée. Voir ci-dessous pour la description détaillée des méthodes de classification. |
4 | Couleur de contour | Définissez la couleur de contour des polygones de la couche d’analyse d’adéquation. |
5 | Largeur du contour | Définissez la largeur du contour des polygones de la couche d’analyse d’adéquation. |
Méthodes de classification
Les méthodes de classification permettent de classer des champs numériques pour la symbologie graduée.
Seuils naturels (Jenks)
Avec la classification par seuils naturels (Jenks)  , les classes sont déterminées par les regroupements naturels inhérents aux données. Les seuils de classe sont créés de manière à optimiser le regroupement des valeurs similaires et à maximiser les différences entre les classes. Les entités sont réparties en classes dont les limites sont définies aux endroits où se trouvent de grandes différences dans les valeurs de données.
, les classes sont déterminées par les regroupements naturels inhérents aux données. Les seuils de classe sont créés de manière à optimiser le regroupement des valeurs similaires et à maximiser les différences entre les classes. Les entités sont réparties en classes dont les limites sont définies aux endroits où se trouvent de grandes différences dans les valeurs de données.
Les seuils naturels sont des classifications propres aux données et ne permettent pas de comparer plusieurs cartes conçues à partir de différentes informations sous-jacentes.
Cette classification repose sur l’algorithme Seuils naturels (Jenks). Pour plus d’informations, consultez Univariate classification schemes dans Geospatial Analysis—A Comprehensive Guide, 6th edition; 2007-2018; de Smith, Goodchild, Longley.
Quantile
Dans une classification par quantile  , chaque classe contient un nombre égal d’entités. Une classification des quantiles est bien adaptée aux données réparties de manière linéaire. Un quantile affecte le même nombre de valeurs de données à chaque classe. Il n’y a pas de classes vides ni de classes avec trop ou trop peu de valeurs.
, chaque classe contient un nombre égal d’entités. Une classification des quantiles est bien adaptée aux données réparties de manière linéaire. Un quantile affecte le même nombre de valeurs de données à chaque classe. Il n’y a pas de classes vides ni de classes avec trop ou trop peu de valeurs.
Etant donné que les entités sont regroupées en nombres égaux dans chaque classe à l'aide de la classification des quantiles, la carte résultante est souvent trompeuse. Il arrive que des entités similaires soient placées dans des classes adjacentes ou que des entités ayant des valeurs très différentes soient dans une même classe. Vous pouvez minimiser cette distorsion en augmentant le nombre de classes.
Intervalle égal
Utilisez la classification par intervalles égaux  pour diviser la plage de valeurs attributaires en sous-plages de même taille. Ceci vous permet de spécifier le nombre d’intervalles, et les interruptions de classe en fonction de la plage de valeurs sont automatiquement déterminées. Par exemple, si vous spécifiez trois classes pour un champ dont les valeurs sont comprises entre 0 et 300, trois classes de plages 0-100, 101-200 et 201-300 sont créées.
pour diviser la plage de valeurs attributaires en sous-plages de même taille. Ceci vous permet de spécifier le nombre d’intervalles, et les interruptions de classe en fonction de la plage de valeurs sont automatiquement déterminées. Par exemple, si vous spécifiez trois classes pour un champ dont les valeurs sont comprises entre 0 et 300, trois classes de plages 0-100, 101-200 et 201-300 sont créées.
L'option Intervalle égal convient particulièrement bien aux plages de données familières, telles que des pourcentages et des températures. Cette méthode met en évidence la quantité d'une valeur attributaire par rapport à d'autres valeurs. Par exemple, elle permet de montrer qu'un magasin fait partie du groupe de magasins ayant réalisé le tiers supérieur de toutes les ventes.
Intervalle géométrique
Une classification d’intervalles géométriques  crée des interruptions de classe basées sur des intervalles de classe ayant une série géométrique. Le coefficient géométrique de ce classificateur peut changer une fois (en son inverse) pour optimiser les plages de classe. L'algorithme crée des intervalles géométriques en réduisant la somme de carrés du nombre d'éléments dans chaque classe. Cela garantit que chaque plage de classes a approximativement le même nombre de valeurs et que le changement entre intervalles est cohérent.
crée des interruptions de classe basées sur des intervalles de classe ayant une série géométrique. Le coefficient géométrique de ce classificateur peut changer une fois (en son inverse) pour optimiser les plages de classe. L'algorithme crée des intervalles géométriques en réduisant la somme de carrés du nombre d'éléments dans chaque classe. Cela garantit que chaque plage de classes a approximativement le même nombre de valeurs et que le changement entre intervalles est cohérent.
Cet algorithme a été développé spécialement pour prendre en charge les données continues. Il constitue un compromis entre les méthodes des intervalles égaux, des seuils naturels (Jenks) et des quantiles. Il crée un équilibre entre la mise en surbrillance des modifications dans les valeurs centrales et les valeurs extrêmes. Il génère un résultat visuellement intéressant et complet d'un point de vue cartographique.
Un exemple d’utilisation de la classification d’intervalles géométriques implique un jeu de données de précipitations dans lequel seulement 15 stations météorologiques sur 100 (moins de 50 %) ont enregistré des précipitations, de sorte que leurs valeurs attributaires sont nulles.
Crédits
Ce processus peut consommer des crédits lorsque la source de données est définie en ligne.
Ressources
Pour en savoir plus sur l’analyse d’adéquation, consultez les ressources suivantes :
Rubriques connexes
Vous avez un commentaire à formuler concernant cette rubrique ?