Business Analyst ライセンスで利用できます。
適合性解析ワークフローでは、定義した条件を満たしているサイトを特定します。 適合性条件は以下のとおりです。
- 人口密度、世帯収入、年間の 1 日当たりの平均交通量など、データ ブラウザーの変数。
- サイト属性などの入力レイヤーのフィールド。
- レイヤーのポイントの位置
条件は、解析中に事前処理、結合、スケール処理されます。 各変数に重みを付けることで、解析に対する影響度を定義できます。 適合性解析の結果、各サイトにはスコアと加重スコアが与えられます。 結果は、[結果] ウィンドウ、マップの適合性解析レイヤーの陰影処理、候補地の属性テーブルに表示されます。
例
ある地域密着型のレストラン チェーンが、新しい市場への展開に関心を持っています。 同社のマーケティング チームは、昼間人口が高い場所、補完的なビジネスが近くにあるかどうか、人口密度が比較的高いエリアなど、レストランの立地として成功を収めた要因を解析しました。 これらの条件を使用し、ウィスコンシン州デーン郡のブロック グループを対象に適合性解析を実行します。 これらのサイトの適合性スコアは 3 か所に返されます。つまり、マップ上に色分けされたブロック グループ、属性テーブル、[結果] ウィンドウ内に表示されます。
結果
解析結果は、各サイトの適合性スコアをカラーコードで表すマップ レイヤーとして、および [サマリー]  、[ヒストグラム]
、[ヒストグラム]  、[散布図]
、[散布図]  、[テーブル]
、[テーブル]  を含む [結果] ウィンドウに表示できます。 適合性解析の [結果] ウィンドウの詳細については、「結果についての調査」をご参照ください。
を含む [結果] ウィンドウに表示できます。 適合性解析の [結果] ウィンドウの詳細については、「結果についての調査」をご参照ください。
演算
各変数のスコア計算を示す設定は、[適合性解析] ウィンドウにあります。 [適合性解析] ウィンドウには、計算を変更するための 2 つのセクション (解析条件を改善するための [条件] タブと、スコアリング方法と条件の重み付けを変更するための [設定] タブ) があります。
条件
[条件] タブには、計算タイプ、影響度、最小値と最大値の範囲の変更など、条件を変更するためのオプションがあります。
1 | 条件の名前 | 条件の名前。 |
2 | 影響度の設定 | 正、負、目標値、ターゲット サイトのいずれかのオプションで条件の影響度が表示されます。 ターゲット サイトが設定されていない場合、デフォルトでは、各適合性条件の影響度が正に設定されます。 ターゲット サイトが設定されている場合、影響度のデフォルトはターゲットになります。 |
3 | ヒストグラム | 条件値の分布を表示します。 目標値またはターゲット サイト値のいずれかが設定されている場合、分布に表示されます。 |
4 | フィルター | スライダーのハンドルを調整し、解析に含まれる最小値と最大値を指定するか、値を手動で入力します。 |
5 | 結果の表示 | このボタンをクリックし、[結果] ウィンドウを開きます。 |
計算では、最初に各値 v を影響度によって変換し、新しい値 v' を生成します。 影響度は正、負、目標値、ターゲット サイトのいずれかに設定できます。 影響度の計算は次のとおりです。
| 影響度 | 説明 | 計算 |
|---|---|---|
正 | 変数の値が大きいほど、最終スコアへの影響が大きくなります。 |  |
逆 | 変数の値が小さいほど、スコアへの影響が大きくなります。 マイナスの影響度とも呼ばれます。 |  |
目標値 | 変数の値が指定した目標値に近いほど、スコアへの影響が大きくなります。 |  |
ターゲット サイト | 変数の値が条件のターゲット サイトの値に近いほど、スコアへの影響が大きくなります。 | 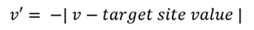 |
スコア
適合性スコアは、複数の条件による情報を単一のスコアとして表すために使用されます。 適合性スコアは、事前処理、加重、結合、最終スコアのスケール処理の 4 つのパートから構成されるプロセスの方法を使用して計算されます。 適合性スコアの設定を変更するには、[適合性解析] ウィンドウの [設定] タブをクリックし、[スコア] をクリックします。
プリセットまたはカスタム スコアリング方法の選択
Business Analyst で、条件の事前処理と結合のための 2 つの事前設定による方法を選択できます。 いずれかの事前設定による方法を選択すると、事前処理および結合のパラメーターが自動的に選択されます。 カスタム方法も選択できます。 [事前設定による方法] ドロップダウン メニューには、3 つのオプションがあります。
- [値の結合 (デフォルト)] - このオプションは、条件のスケール処理された値を合計し、各条件が最終スコアに同様に寄与します。
- このオプションでは、[最小最大] による方法を事前処理に使用します。
- このオプションは、[合計] による方法を結合に使用します。
この事前設定による方法は、すべての条件を結合した効果を評価するのに役立ちますが、外れ値の影響を受けやすくなります。 極値は、最終スコアに過度な影響を与える可能性があります。
- [複合の差分] - このオプションでは、スケール処理済みの値の幾何学的平均値を使用します。
- このオプションでは、[最小最大] による方法を事前処理に使用します。
- このオプションでは、[幾何学的平均値] による方法を結合に使用します。
この事前設定による方法は、条件の単位またはスケールが異なり、値間の相対的差異を強調する場合に役立ちます。 外れ値の影響を受けにくいため、条件に割合や比率が含まれている場合に役立ちます。 スコアが高くなるのは、複数の条件に高い値が存在する場合のみです。 その結果、単一の条件における極値が、スコアに過度な影響を与えることはありません。
- [カスタム] - このオプションでは、事前処理と結合方法を選択できます。これらについては、以下で詳しく説明します。
事前処理による方法の選択
事前処理では、変数を共通のスケールに標準化します。 [事前設定による方法] ドロップダウン メニューで [カスタム] オプションを選択した場合は、[事前処理による方法] パラメーターを使用して一般的なスケール方法を選択できます。 選択した方法はすべての変数に適用され、結果のフィールドが出力で提示されます。
事前処理による方法とその計算は次のとおりです。
| 事前処理による方法 | 説明 | 計算 |
|---|---|---|
最小最大 | この事前処理による方法では、各変数の最小値と最大値を使用して、変数が 0 ~ 1 でスケールされます。 入力変数の分布が保持され、わかりやすい 0 ~ 1 のスケールを使用するため、この方法は最も簡単です。 ただし、データの外れ値はスコアに影響します。 |
|
パーセンタイル | この事前処理による方法では、データ値のランクをスケール処理することで、変数が 0 〜 1 のパーセンタイルに変換されます。 パーセンタイルのスケール処理を使用し、特に傾斜分布や外れ値が多いデータを操作する場合に、実際の値の大きさではなく、他のサイトとの比較における位置に基づいてサイトをランク付けします。 この方法では、外れ値または傾斜分布はスコアに影響しません。 |
|
ZScore | この事前処理による方法では、平均値を減算して標準偏差 (または Z スコア) で割ることで、各条件を標準化します。 Z スコアは、平均値を上回る標準偏差または下回る標準偏差の数です。 この方法は、異なる単位を使用するデータを正規化することで、共通のスケールを作成する場合に役立ちます。 平均値を上回る値には正の Z スコアが付与され、平均値を下回る値には負の Z スコアが付与されます。 |
|
未処理 | このオプションでは、変数の元の値を使用します。 事前処理は適用されないため、データは入力条件のスケールを維持します。 この方法は、条件が割合値などの比較可能なスケールである場合や、条件が他のツールを使用してすでに事前処理されている場合に役立ちます。 |
|




結合方法の選択
結合では、変数を 1 つの値に結合します。 [事前設定による方法] ドロップダウン メニューで [カスタム] オプションを選択した場合は、[結合方法] パラメーターを使用して結合方法を選択できます。
結合方法とその計算 (c は条件の数を表す) は、次のとおりです。
| 結合方法 | 説明 | 計算 |
|---|---|---|
合計 | この結合方法では、加重スコアを合計します。 この方法は非乗法です。つまり、条件にそれぞれの重みを乗算することで重みが適用されます。 |
|
平均 | この結合方法では、加重スコアの平均を使用します。 この方法は非乗法です。つまり、条件にそれぞれの重みを乗算することで重みが適用されます。 |
|
Product | この結合方法では、加重スコアの積を使用します。 この方法は乗法です。つまり、各条件をそれぞれの重みで累乗することで重みが適用されます。 |
|
幾何補正平均 | この結合方法では、加重スコアの幾何補正平均を使用します。 この方法は乗法です。つまり、各条件をそれぞれの重みで累乗することで重みが適用されます。 |
|
")
")
")
")
注意:
条件に負の値が含まれており、事前処理による方法の代わりに [未処理] を選択した場合、[結合方法] メニューから [プロダクト] または [幾何学的平均値] を選択すると、条件スコアが NULL になります。 これらの NULL 値は、最終スコアに影響しません。
最終スコアのスケール処理の選択
最終スコアのスケール処理では、結合されたスコアを意味のある最終スコア値に変換します。 [最終スコアのスケール] パラメーターを使用して最終スコア処理の方法を選択できます。
最終スコアのスケール処理と、その計算は次のとおりです。
| 最終スコアの方法 | 説明 | 計算 |
|---|---|---|
0 ~ 1 | この最終スコアのスケール方法では、0 を最小値、1 を最大値として最終スコアを計算します。 0 〜 1 の範囲内で、他のすべての値は比率を維持したままスケール処理されます。 |
|
0 ~ 100 | この最終スコアのスケール方法では、0 を最小値、100 を最大値として最終スコアを計算します。 0 〜 100 の範囲内で、他のすべての値は比率を維持したままスケール処理されます。 |
|
なし | このオプションでは、データのスケール処理を行わず、元のデータを保ちます。 このオプションは、結合された値の分布を保持する場合に役立ちます。 |
|
")
")
")
条件の重み付け
条件の重みとは、各条件が最終スコアに寄与する際に、その相対的な重要度を表します。 重み付けの設定を変更するには、[適合性解析] ウィンドウの [設定] タブをクリックし、[加重] をクリックします。 [加重] セクションには、解析内の条件とその重みが表示されます。 デフォルトでは、適合性条件は等しく加重されています。 ただし、一部の条件が他の条件よりも重要である場合は、異なる加重を適用する必要があります。
2 つの重み付けの方法があります。
- 合計に対する割合
- 相対
合計に対する割合
合計に対する割合として条件の加重を設定できます。すべての条件は合計で 100% になる必要があります。 条件の加重を増減すると、それに合わせて残りの各条件の加重が自動的に増減されます。 [条件のロック] ボタン  をクリックすると、条件の値をロックできます。 ロックされた条件は、変更を加えたときに、自動の再加重から除外されます。
をクリックすると、条件の値をロックできます。 ロックされた条件は、変更を加えたときに、自動の再加重から除外されます。
たとえば、3 つの条件があり、1 つの条件が他の 2 つよりも 2 倍重要である場合、50%、25%、25% の重みを使用します。
相対
相互に相対的な条件の加重を設定できます。 デフォルトですべての重みが 1 に設定され、各条件の加重が均等になります。 これらの値を調整することで、ある条件の、他のすべての条件に対する相対的な重要性を変更できます。
たとえば、条件の 1 つを重み 2 に変更し、他のすべての条件を 1 のままにすることで、最終スコアへの寄与において他の条件の 2 倍重要になります。
重みとスコアの計算
選択した結合方法は、重みの適用方法に影響を与えます。 [結合方法] メニューでの選択に応じて、非乗法または乗法の方法が選択されます。 [合計] および [平均] による方法では、各条件にそれぞれの重みを乗算することで重みが適用されます。 [プロダクト] と [幾何補正平均] の方法では、各条件をそれぞれの重みで累乗することで重みが適用されます。
非乗法 (合計、平均) |  |
乗法 (プロダクト、幾何補正平均) |  |
加重の設定に関するベスト プラクティス
加重の値は、結果として得られるスコアに大きな影響を与える可能性があります。 同じ加重を維持する場合、あるいは特定の条件を優先するように重みを変更する場合でも、加重の選択は主観的であり、確固たる根拠が必要になります。 条件の選択と同様、適切な加重に関するアドバイスについては、サブジェクト マター エキスパート (主題専門家) に相談してください。 重みは、世論調査などの他の方法を使用して定義することもできます。
シンボル表示
[適合性解析] ウィンドウの [設定] タブで、ArcGIS Pro シンボルのサブセットが提供されます。 適合性解析レイヤーの表示設定と作図は、適合性解析への変更後も維持されるパラメーターを使用してカスタマイズできます。
1 | クラス数 | 出力データで色分けしてシンボル表示したデータ グループの数。 |
2 | 配色 | 出力データを表すために使用される色の範囲。 選択した配色は、変化が適用された後も維持されます。 |
3 | 分類方法 | 分類方法を使用すると、等級シンボルの数値フィールドを分類できます。 分類方法の詳細については、以下をご参照ください。 |
4 | アウトライン色 | 適合性解析レイヤーのポリゴンのアウトライン色を設定します。 |
5 | アウトライン幅 | 適合性解析レイヤーのポリゴンのアウトライン幅を設定します。 |
分類方法
分類方法を使用すると、等級シンボルの数値フィールドを分類できます。
自然分類 (Jenks)
自然分類 (Jenks)  では、クラスはデータ値の自然なグループ化に基づいています。 クラス閾値は、類似している値を最適にグループ化し、クラス間の差異を最大化するように作成されます。 フィーチャは、データ値の差異が比較的大きい部分に境界が設定されるようにクラスに分割されます。
では、クラスはデータ値の自然なグループ化に基づいています。 クラス閾値は、類似している値を最適にグループ化し、クラス間の差異を最大化するように作成されます。 フィーチャは、データ値の差異が比較的大きい部分に境界が設定されるようにクラスに分割されます。
自然分類手法は、データ固有の分類方法で、異なる基礎情報から構築された複数のマップの比較には有用ではありません。
この分類方法は、Jenks の自然分類アルゴリズムに基づいています。 詳細については、「Univariate classification schemes」(Geospatial Analysis—A Comprehensive Guide, 6th edition; 2007 – 2018; de Smith, Goodchild, Longley) をご参照ください。
分位
等量分類  では、各クラスに同じ数のフィーチャが含まれます。 等量分類は、線形に分散しているデータに適しています。 等量分類では、各クラスに同じ数のデータ値を割り当てます。 空のクラスや、値の数が多すぎたり少なすぎたりするクラスはありません。
では、各クラスに同じ数のフィーチャが含まれます。 等量分類は、線形に分散しているデータに適しています。 等量分類では、各クラスに同じ数のデータ値を割り当てます。 空のクラスや、値の数が多すぎたり少なすぎたりするクラスはありません。
等量分類では、各クラスのフィーチャが同じ数でグループ化されるため、作成されたマップの意図が正しく伝わらない場合がよくあります。 似たようなフィーチャが異なるクラスに分類されたり、大きく異なる値を持つフィーチャが同じクラスに分類されたりすることがあります。 この歪みは、クラスの数を増やすことにより最小限に抑えることができます。
等間隔
等間隔分類  では、属性値の範囲を同じサイズのサブ範囲に分割します。 これを使用して間隔数を指定でき、値の範囲に基づいてクラス閾値が自動的に決定されます。 たとえば、値の範囲が 0 ~ 300 であるフィールドに対して 3 つのクラスを指定すると、0 ~ 100、101 ~ 200、201 ~ 300 という範囲の 3 つのクラスが作成されます。
では、属性値の範囲を同じサイズのサブ範囲に分割します。 これを使用して間隔数を指定でき、値の範囲に基づいてクラス閾値が自動的に決定されます。 たとえば、値の範囲が 0 ~ 300 であるフィールドに対して 3 つのクラスを指定すると、0 ~ 100、101 ~ 200、201 ~ 300 という範囲の 3 つのクラスが作成されます。
等間隔分類は、パーセンテージや温度など、一般的なデータの範囲に最適です。 この方法では、特定の属性値について、他の属性値と比較したときの総数を強調することができます。 たとえば、ある店舗が、合計売上の上位 1/3 を構成する店舗のグループに属していることを示すような場合です。
等比間隔
等比間隔分類法  では、等比級数を持つクラスの間隔に基づいてクラス閾値が作成されます。 この分類法におけるジオメトリック係数を (逆数に) 変更して、クラスの範囲を最適化することができます。 このアルゴリズムは、各クラスの要素数の二乗和を最小化することで、幾何学的間隔を作成します。 これにより、各クラスの範囲にクラスごとにほぼ同じ数の値が含まれ、間隔ごとの差が一定に保たれます。
では、等比級数を持つクラスの間隔に基づいてクラス閾値が作成されます。 この分類法におけるジオメトリック係数を (逆数に) 変更して、クラスの範囲を最適化することができます。 このアルゴリズムは、各クラスの要素数の二乗和を最小化することで、幾何学的間隔を作成します。 これにより、各クラスの範囲にクラスごとにほぼ同じ数の値が含まれ、間隔ごとの差が一定に保たれます。
このアルゴリズムは、連続的なデータに対処するために特別に設計されたものです。 等間隔分類、自然分類 (Jenks)、および等量分類の折衷的な方法です。 中間値と極値の重要な変化の間でバランスを取ることで、視覚効果の高い、地図的にも包括的な結果が生成されます。
等比間隔分類を使用する例としては、降雨量のデータセットを使用する際に、100 の測候所のうち 15 の (50% 未満の) 測候所では降水量が記録され、残りの測候所では降水量が記録されていないために属性値が 0 になる場合などがあります。
著作権
データ ソースがオンラインに設定されている場合、このワークフローはクレジットを消費することがあります。
リソース
適合性解析の詳細については、次のリソースをご参照ください。